
Why Most High Traffic Websites Fail to Scale
Summarize with
Think high traffic equals success? Not without the right architecture—many sites collapse under their own popularity.
Challenges arise when our clients run campaigns or launch new products into the market. A recent launch triggered a 1031% surge in traffic!
Let’s explore exactly what happened and explain how we’ve set up our infrastructure to easily deal with surges like this.
Key takeaways
- Scalable Architecture: Core dna’s platform uses modular infrastructure layers that can be scaled independently to handle massive traffic spikes efficiently.
- Robust CDN & DNS Strategy: With StackPath CDN and advanced DNS solutions like Anycast and ALIAS records, content is delivered quickly and reliably worldwide.
- Smart Load Balancing: Their load balancing layer distributes traffic evenly across servers, avoiding overload and ensuring consistent performance.
- Optimized Server Stack: A dual NGINX-Apache setup, Memcached caching, and AWS services (EFS, RDS) ensure high performance, reliability, and unlimited scalability.
In a hurry? Get Scalable Web Architecture
On this page:
Headless CMS guide
What causes a 1031% surge in traffic
An Australian client of ours is one of the world’s top 20 concert promoters. As you might expect, they experience massive surges in traffic when tickets for the most famous artists go on sale.
Here’s how crazy it looked when they announced a concert for British singer-songwriter Sam Smith:
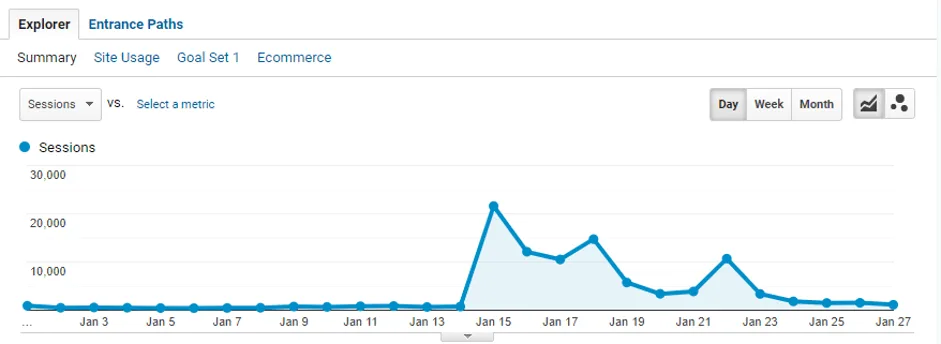
That’s just for ONE artist. They have TONS of artists and shows running concurrently.
Sidenote: If you didn’t know who Sam Smith is, he’s kind of a big deal; won Grammy several times, 8.2M followers on Twitter, 12.5M subscribers on YouTube, 14.6M followers on Instagram.
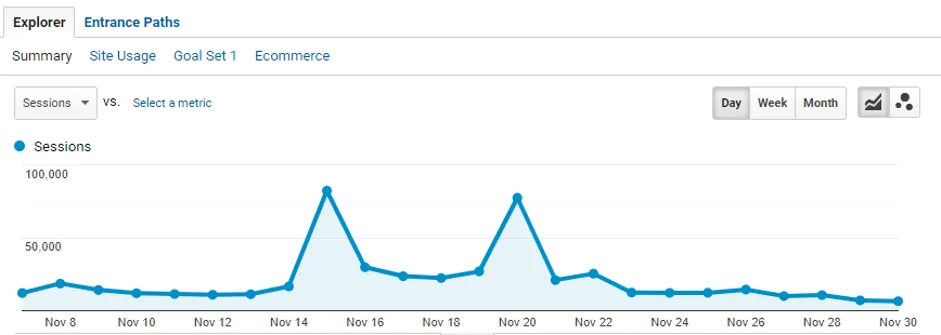
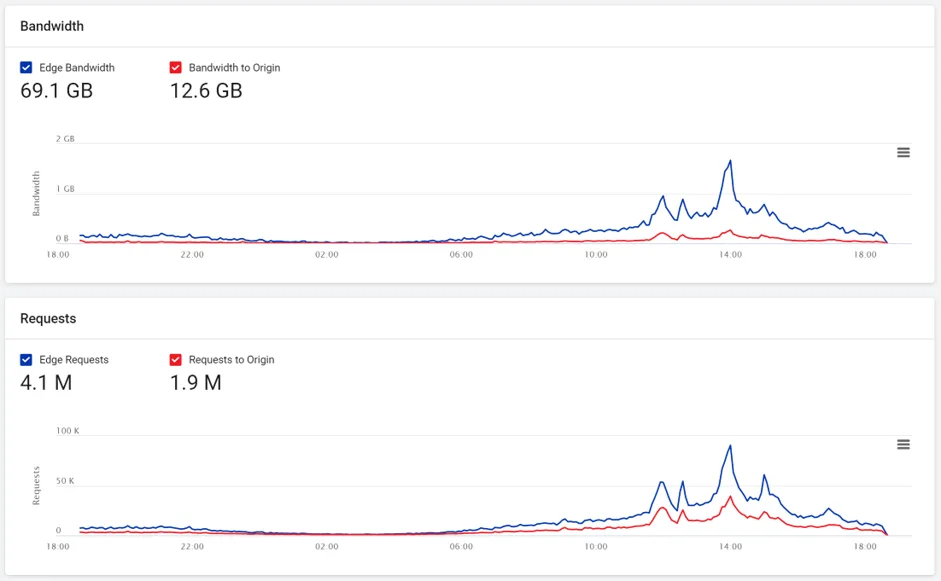
Late last year, they announced the return of triple Grammy® award-winning Californian rockers Tool, and here’s a look at the traffic surge:
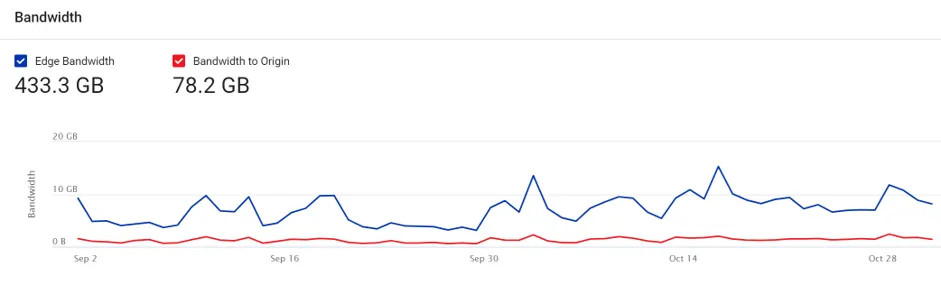
Before the day of the ticket launch, the Core dna client’s daily traffic averaged 6.7 Gb on CDN servers, of which 1.2 Gb was passed on to Core dna application servers with the rest delivered from CDN cache.
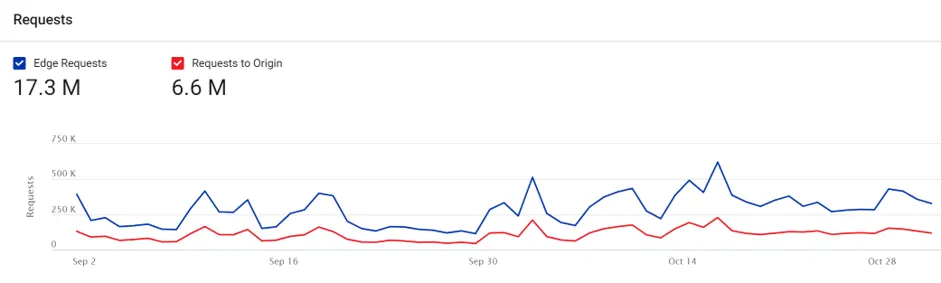
In terms of requests, the CDN usually receives 283,000 requests daily. Only 107,000 of these requests are passed on to the origin servers (the server that contains the original web page) with the rest served from cache.
Within the 24-hour period, which included the pre-sale event, the client’s website experienced a 1031% surge in traffic and a 1050% increase in requests to our CDN. In other words, the site consumed ten days of its “normal” traffic in one day, and most of this traffic was spread over just 6 hours.
So, how do we set up our infrastructure to handle such a surge?
Handling such a massive traffic surge is an immense challenge, but one we can manage, thanks to our capacity and scaling strategy.
We break our platform down into self-contained ‘segments’ that we can dynamically increase or decrease independently, adding capacity precisely where it’s needed, at any given moment.
Our infrastructure is made up of multiple layers called Platform Layers.
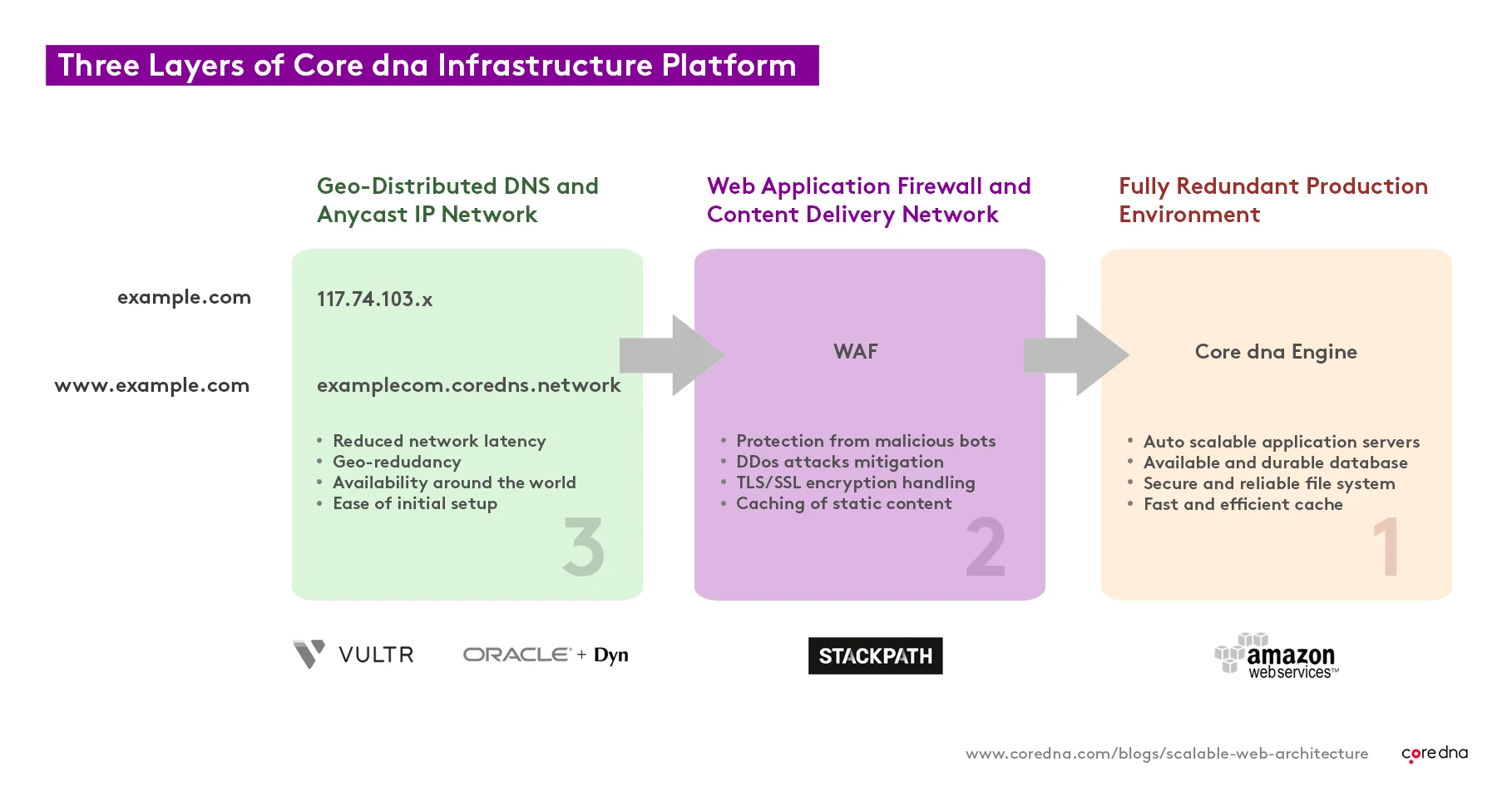
(How to create a scalable website architecture: Core dna’s 3-layer infrastructure layer)
Each platform layer consists of modular components, and each of those can easily be replicated or replaced in the event of an issue, or when extra capacity is needed.
Let’s break it all down and see how each of these layers work:
1. A CDN delivers data direct from your local data center
A CDN (Content Delivery Network) is a geographically distributed group of servers that work together to deliver content, fast. A CDN allows for the transfer of assets needed for loading things like images, videos, and HTML pages.
They’re super-important for the modern web and are becoming increasingly popular with the majority of traffic for sites like Facebook, Netflix, and Amazon served through CDNs.
CDN platforms work by having large data centers distributed across the globe. Traffic for a website is delivered to the closest data center to the originating request, making things fast and cheap.
A user in Australia, for example, will receive the website from a data center located in Australia, whereas a user in Germany might get their response from a local data center in Berlin.
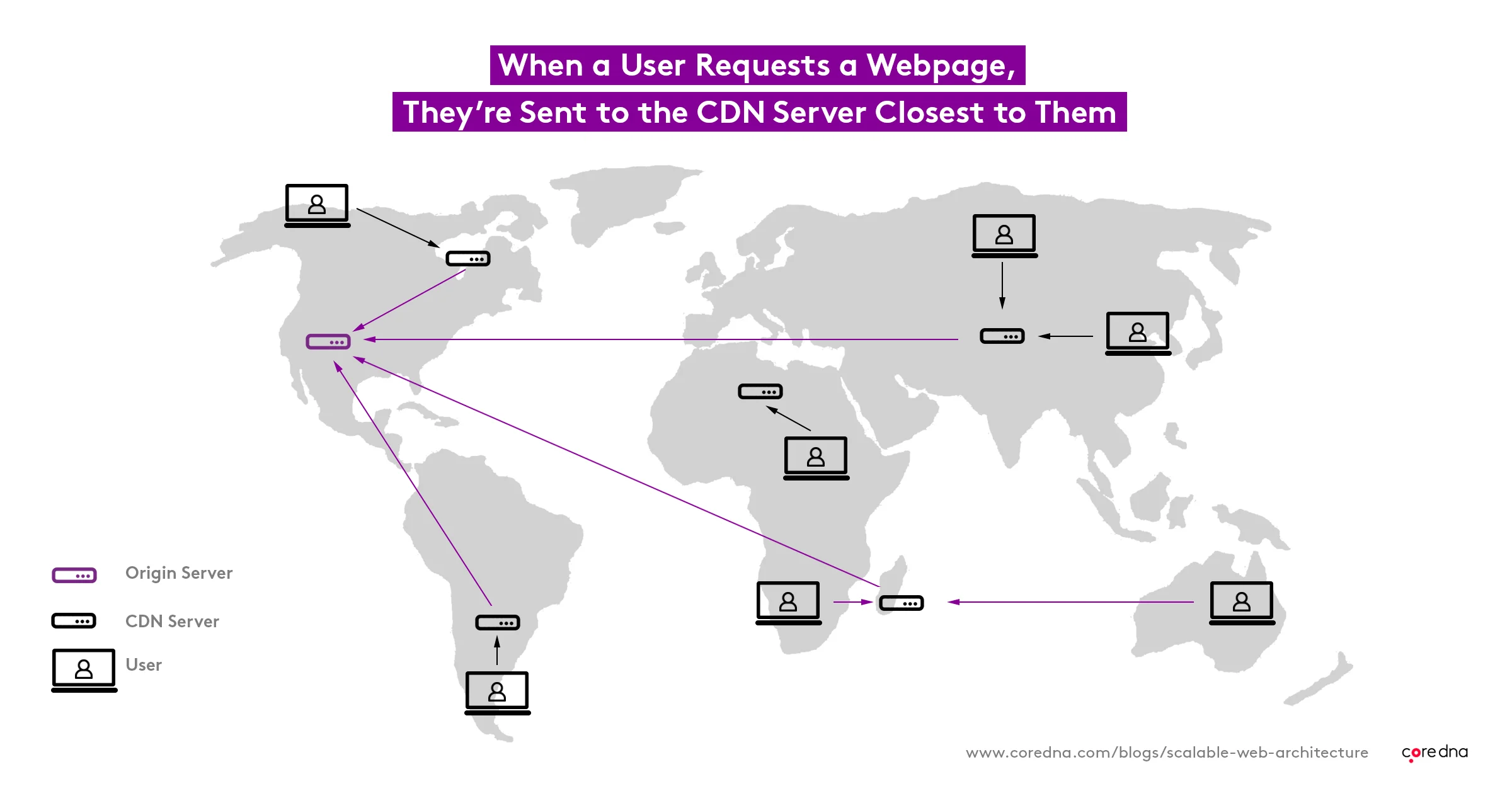
The physical distance that data needs to travel is greatly reduced, and the shorter the distance travelled, the higher the speed a website loads, and the fewer resources are consumed (saving money!)
CDN caching is also really important. CDN servers can save things like images and videos in a cache, which can be accessed more quickly when they’re needed again. When a web request first hits a CDN server, it passes it on to the actual website server. The actual server sends back the relevant data to the CDN, and it’s saved in its cache to be used again.
Core dna’s CDN provider of choice is Stackpath, and every Core dna client receives the benefits of Stackpath CDN as part of the Core dna platform. StackPath’s resources are vast, and its ability to scale is virtually limitless. They have a large team keeping a close eye on the servers at all times so they can cope with any traffic surge.
2. Our DNS forwarding layer solves one of the Internet’s oldest problems
The DNS (Domain Name System) is used globally across the entire internet and is fundamental to how the whole thing works. So, when a user makes a request to a website, the very first thing their internet browser will do is make a DNS request asking where that website is located.
Assuming the website exists and has been set up correctly, the browser gets an IP address back, which it can then use to contact the server that’s hosting the website, and finally access it.
In a nutshell: “DNS is like the phone book of the internet.”
Anyhow, back in the early days of the internet, this was quite straightforward - each server had one unique IP address that never changed.
But, this created a problem:
What to do when the server on that IP address fails for any reason? You can’t just pick up and move an IP address!
And there’s an additional problem too:
How to deal with a setup using multiple servers - they can’t all share a single IP.
The invention to solve this problem was a new DNS record type, called a CNAME, that’s much more flexible and can be changed dynamically.
A CNAME record can return different IP addresses depending on where in the world a user’s located.
CNAME records have opened the door to the enormous benefits of the CDN platform, but there’s just one problem (yes, another one):
You can’t use them on an apex domain (the root domain ie, example.com.) For the apex domain, you’re stuck with your fixed IP address and all the problems that entail.
A few DNS and CDN providers have come up with solutions to this niggling issue, but it remains pretty pervasive. Amazon, for example, offers what they call ALIAS DNS records, which function like a CNAME record from a user perspective, but on a technical level, appear to be a regular traditional DNS record.
Core dna’s DNS provider, Oracle, offers a similar ALIAS solution, which lets us make full use of our CDN platform. It’s the most common answer to this problem.
But, what about our clients using traditional DNS systems?
For them, this layer is irrelevant. We need a solution that lets these customers host their websites on the Core dna platform too. So, we use a relatively new IP routing technology called Anycast, in addition to our private range of IPs that we own.
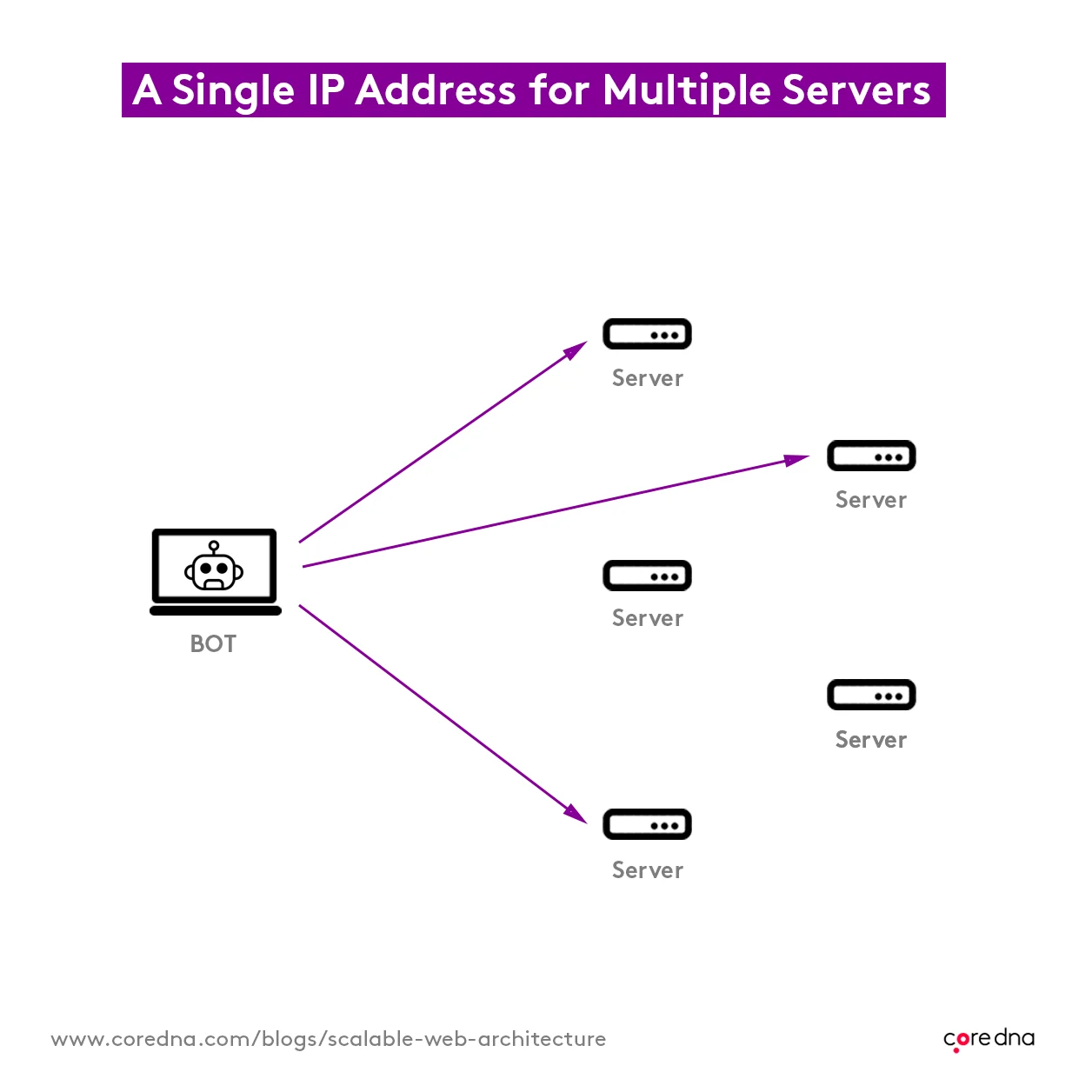
Anycast makes it possible to use a single IP address for multiple servers, just like CNAME records do. So, when someone accesses specific IPs, they’re directed to the closest server to their location. Our clients can use traditional DNS systems, with fixed IP addresses, and still benefit from the same level of flexibility and reliability that a CDN system offers.
3. The traffic cop that is the load balancing layer
The load balancing layer is like a traffic cop. It sits in front of the servers and directs client requests ‘evenly,’ achieving maximum efficiency, by leveraging those with the most capacity and stopping any servers from becoming overburdened.
This layer detects when an application server is down or malfunctioning and avoids directing any traffic its way. If an application server should fail, the end-user experience won’t be affected.
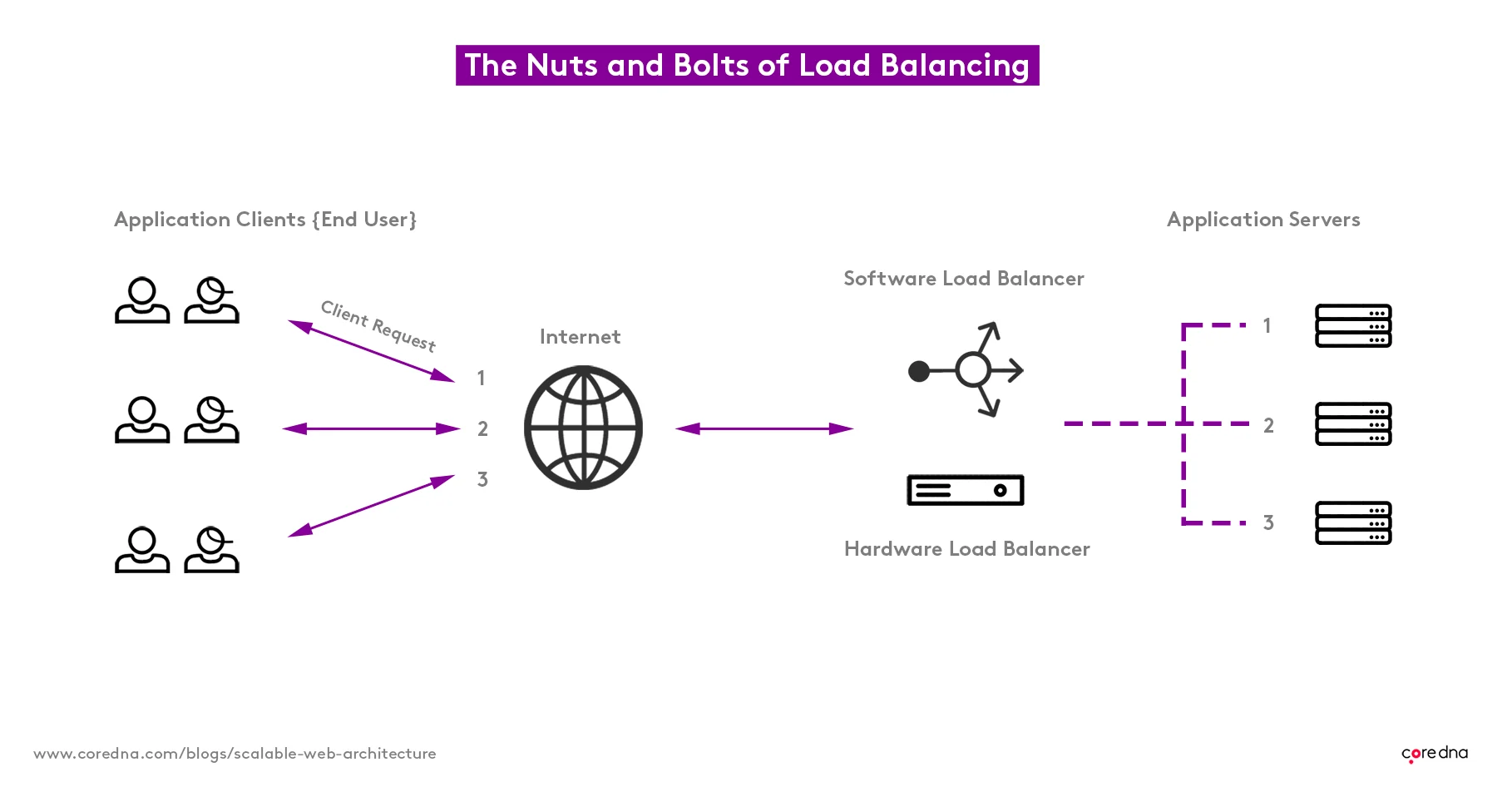
We can add new application servers to the system on the fly, to deal with any surges in traffic. The load balancers can tell when new servers are ready to rock and dynamically allocate traffic to them as required.
4. A dual-stack of NGINX and Apache squeezes every last drop of resource from each server
We’ve set up our application servers using two pieces of technology. First, we’ve used NGINX, which serves all static web content like images, javascript, and other files that don’t require processing. Then, we use the Apache Web Server to handle anything more hardcore.
NGINX is excellent because it’s very light and efficient and serves static resources fast with little computing power. But when a site request comes through for a page generated by Core dna, we’ll use Apache, because NGINX isn’t quite powerful enough to execute the PHP that it’s written in.
Having a dual-stack approach lets us squeeze the maximum capacity out of every server at our disposal.
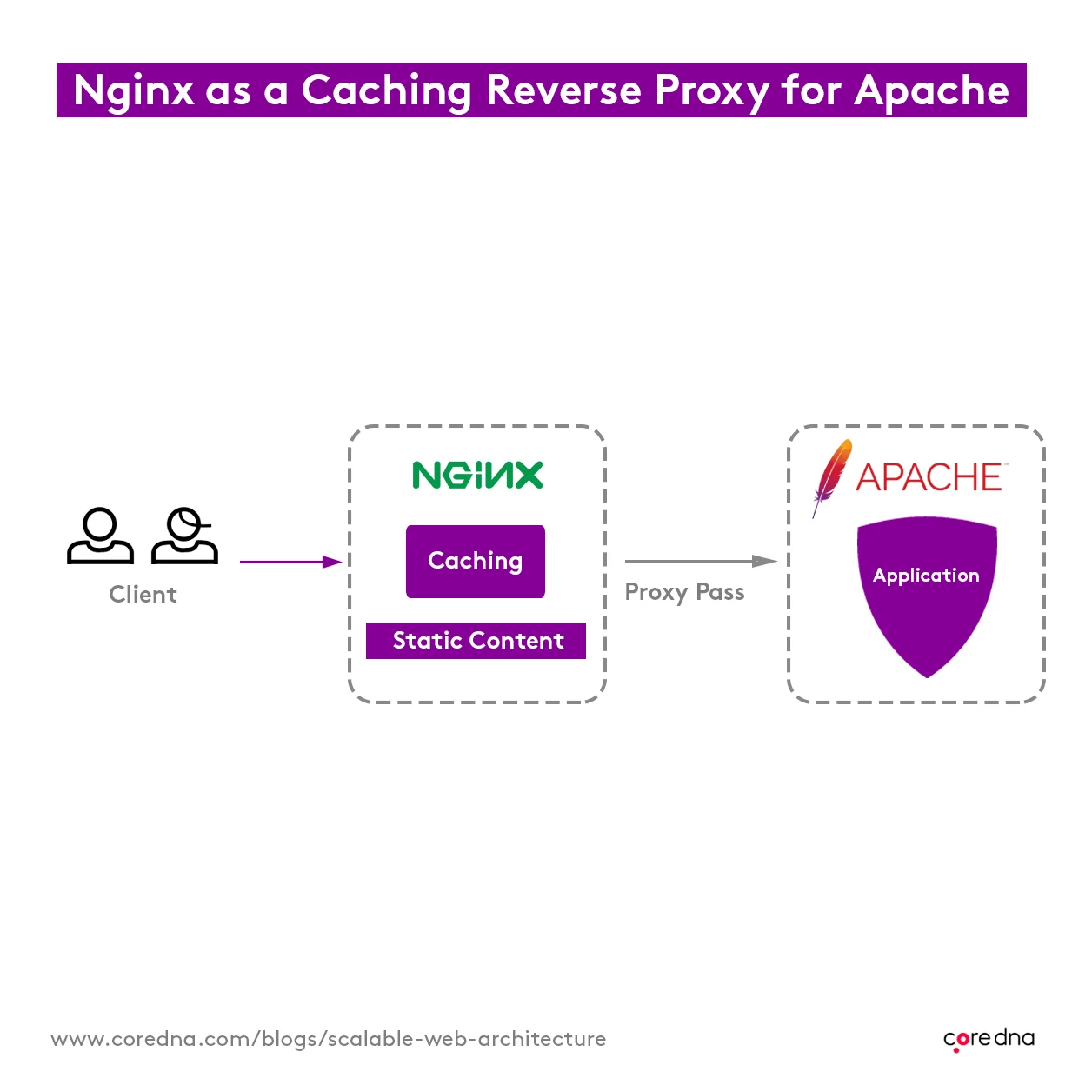
We configure all of our application servers in exactly the same way - none are unique. Standardizing like this streamlines the process when we create new application servers to increase capacity in response to high traffic events. Additionally, this means if an application server fails, critical information is safe.
5. Memcached saves time and lightens the load
A cache stores data for a certain amount of time so it can be quickly used again in the future. Our caching layer is an implementation of a system called Memcached, and it’s got a few great things going for it…
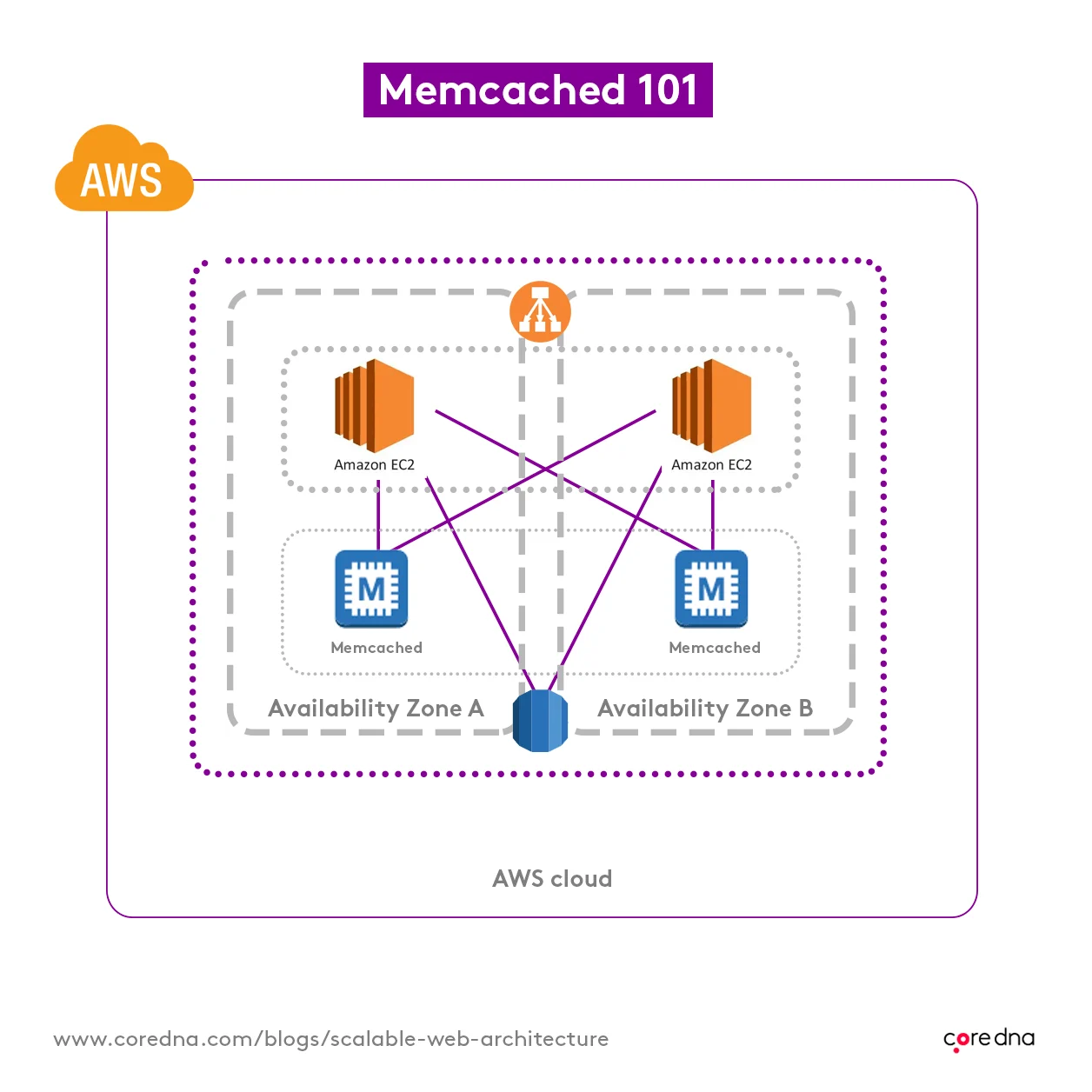
When a user accesses a Core dna website, they’re assigned a ‘session’ which tracks everything they do on the site. If they log in, the session will keep track of that. If they’re shopping on an eCommerce site, the session will track what’s in the cart.
We can’t store that session on an individual application server, because a user could be receiving web pages from multiple servers running at the same time. Every single application server needs access to all of the sessions at any given moment.
Our solution?
We move sessions to a centralized location where each application server can access them at once. Memcached stores all sessions extremely quickly, letting Core dna applications access their session data swiftly.
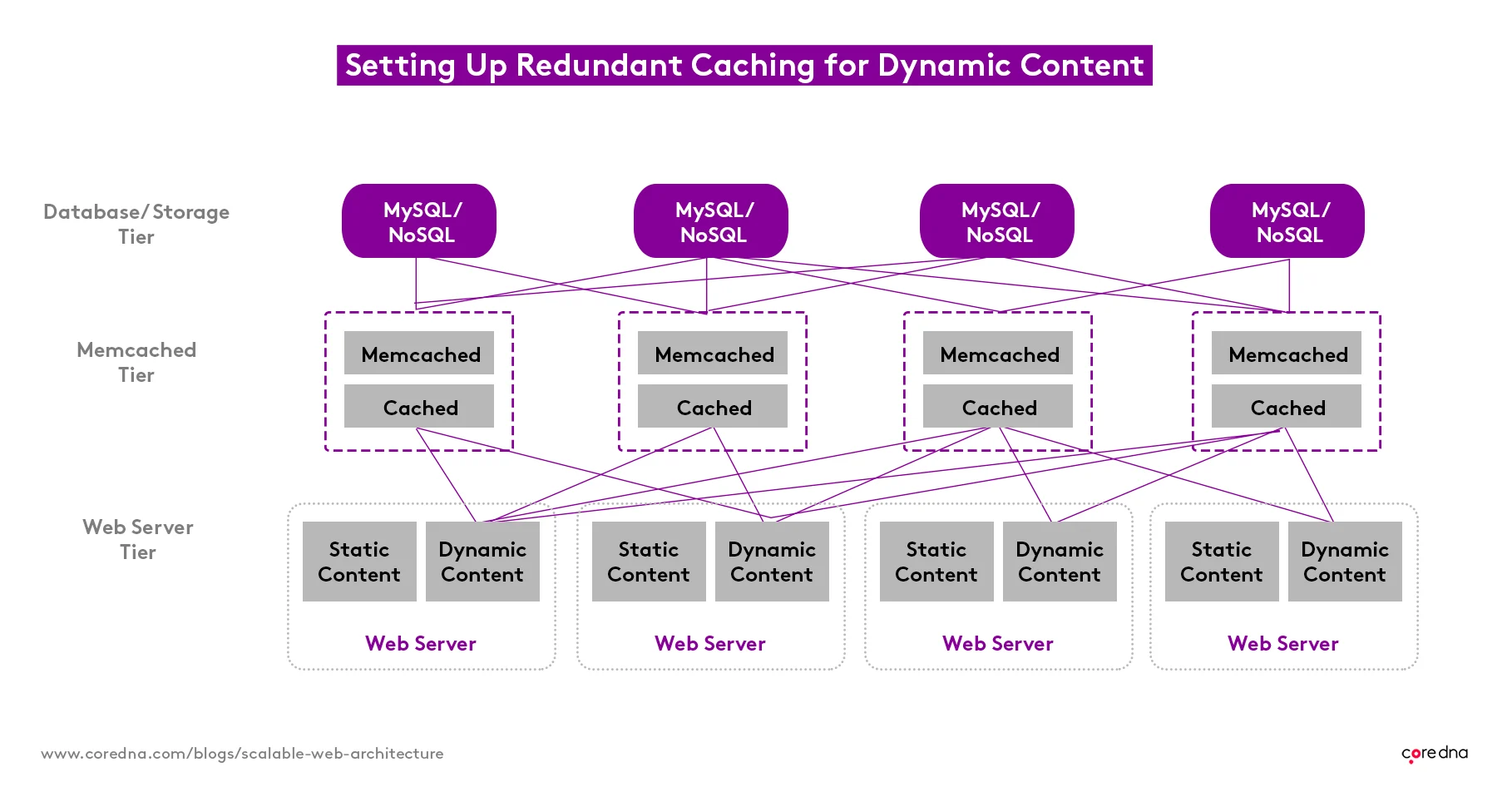
But, it’s not just sessions we store; we cache several other things in the Memcached system.
If we get a large piece of data that takes ages to retrieve but rarely changes, for example, we’ll cache that too, saving time and reducing the amount of compute-intensive traffic that database servers have to deal with.
6. Amazon EFS fuels our file layer
Amazon Elastic File System (EFS) ensures every Core dna file is available to all application servers simultaneously.
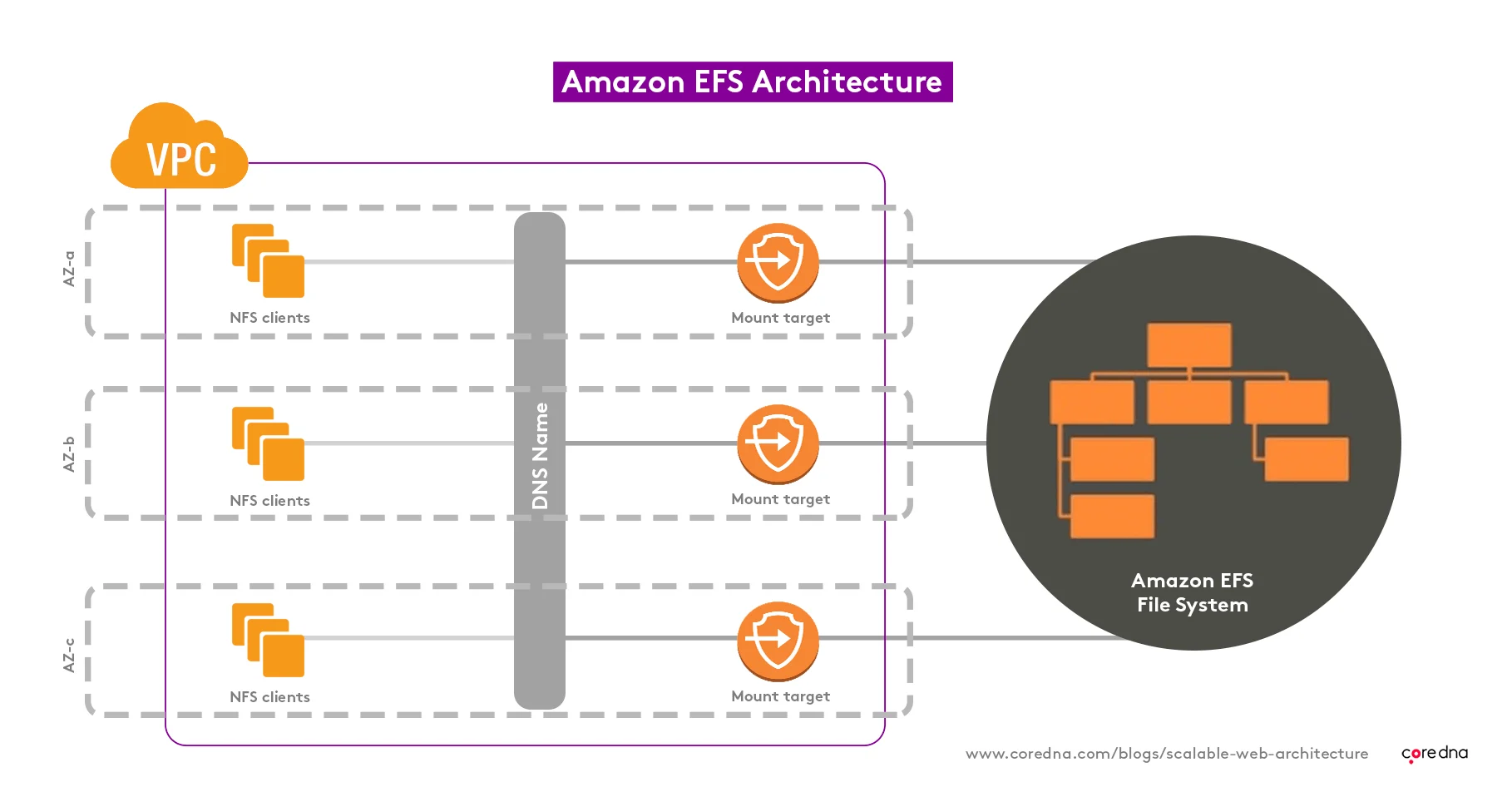
It’s offered by Amazon as a black box solution and comes with a mighty impressive set of built-in monitoring and analytics tools.
We use it to edit, on the fly, the amount of throughput needed to files, increasing capacity in response to surges in traffic.
The beauty of using Amazon’s services is their data centers are gargantuan! We can tap into as much additional capacity as we could ever need.
7. We never run out of scaling capacity with Amazon RDS
We also rely on AWS (Amazon Web Services) for our database layer, this time RDS (Relational Database Service.) Like EFS, RDS offers us near-unlimited scaling capacity.
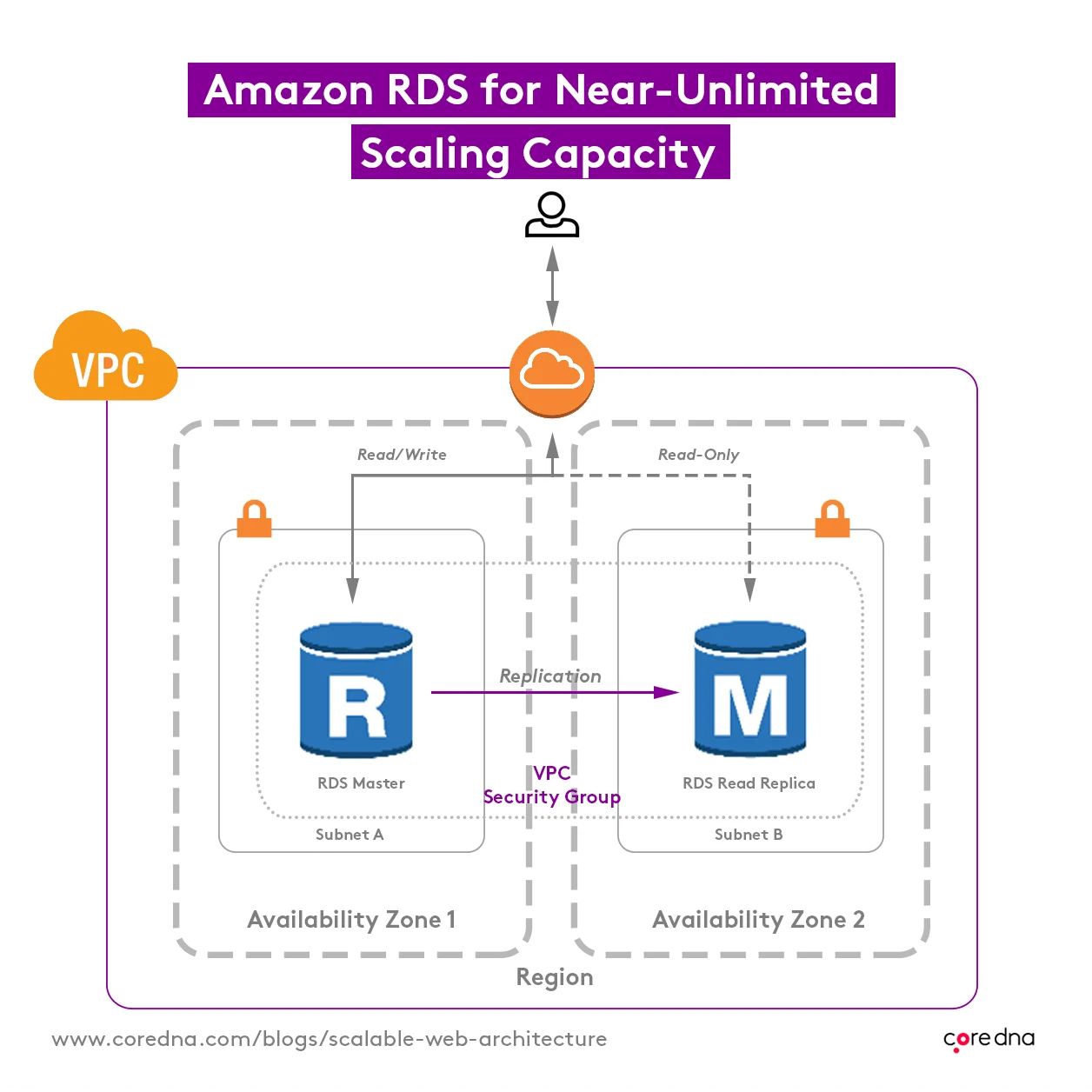
Amazon’s Aurora technology lets us run multiple database servers in different data centers that can all communicate with and replicate data between each other.
If we need to increase database capacity, we can increase the size of one server at a time, minimizing disruption.
8. We load balance our search layer
We’ve separated out our search layer too, using a similar system to that which we use for our application servers.
Load balancers track all our search servers, balancing traffic between them, dodging any that are experiencing difficulties. This configuration makes adding new servers quick and easy if and when additional capacity is required.
Break things down to speed things up
The best strategy for dealing with capacity and redundancy is to break systems down into their constituent, modular parts. And, that’s precisely what Core dna’s capacity and scaling strategy is all about!
Only then can we allocate resources directly to the areas that need them most, and will use them most efficiently, ensuring operations are performed in a fast and reliable way, even when traffic has surged 1031%!
If you need a scalable platform for your content and commerce sites, let’s chat!
Have questions? Speak with our experts to find your ideal content solution
Summarize with











