
llms.txt: do you need it, and does it actually work?
Summarize with
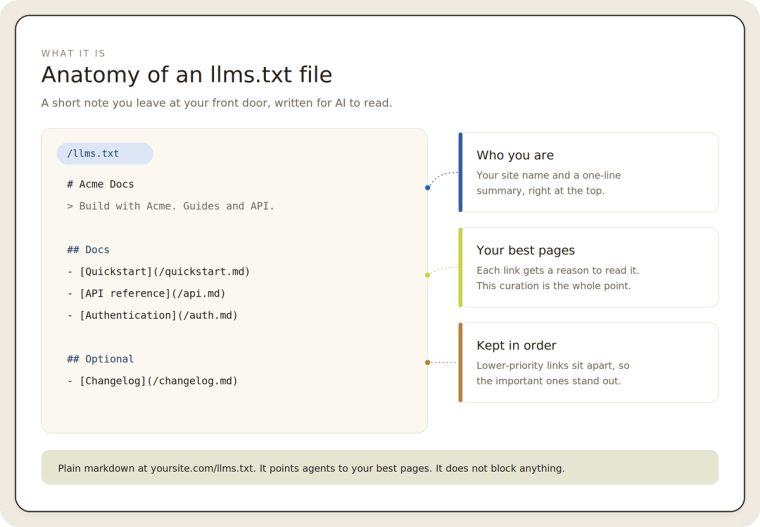
llms.txt is a plain markdown file you place at the root of your domain, at yoursite.com/llms.txt. It gives large language models a curated map of your most important pages, written in clean text instead of cluttered HTML. Think of it as a table of contents built for machines rather than people.
That is the whole idea. The debate is about whether any machine is actually reading it.
Here is the honest answer, up front: adding llms.txt costs almost nothing and carries almost no risk. But the claim that it lifts your visibility in ChatGPT, Claude, Perplexity, or Google's AI results is unproven. Most of the noise around it is closer to folklore than fact. The file is real. The results people promise from it are not.
Key takeaways
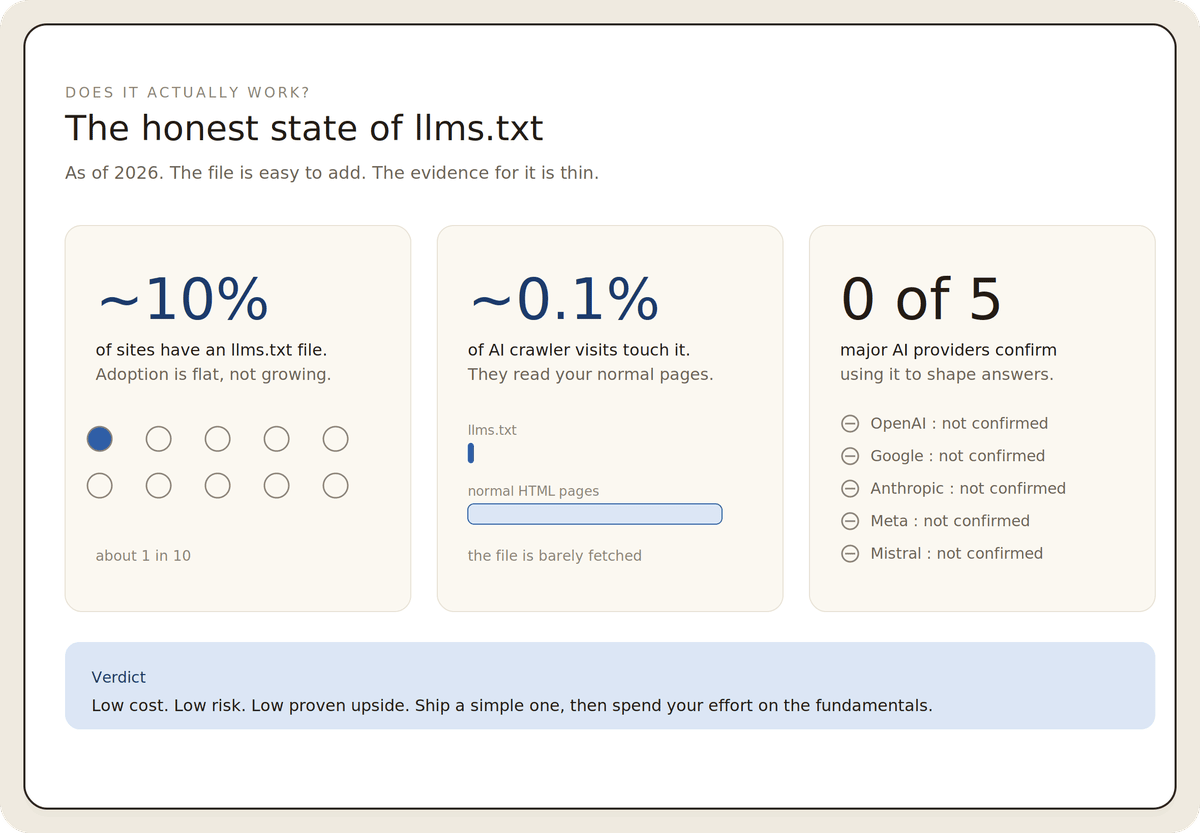
- llms.txt is a markdown file at your site root that points AI models to your best content. It is a map, not a lock: it cannot block any crawler.
- Adoption sits at about 10% of sites, and the major AI search crawlers mostly skip the file and read your normal pages instead.
- No major AI provider, including OpenAI, Google, Anthropic, and Meta, has confirmed using llms.txt in its production answer systems. Controlled studies found no link to more citations.
- The real, proven use is developer tooling: AI coding assistants like Cursor and GitHub Copilot read it to fetch documentation cleanly.
- It is cheap insurance, so ship a simple one, then spend your real effort on content quality, E-E-A-T, structured data, and crawlability.
What is llms.txt, exactly?
The format was proposed by Jeremy Howard of Answer.AI in September 2024. The pitch was practical: AI systems waste effort crawling and parsing full HTML pages full of navigation, scripts, and ads. A short markdown file could point them straight at the pages that matter, in a format they read efficiently.
A basic file looks like a heading with your site name, a one-line description, then a list of links to your key pages with a sentence explaining each one. Some sites also publish llms-full.txt, which packs the full text of those pages into one document for deeper ingestion. Most sites only need the shorter version.
One point is worth making early, because it is a common mix-up. llms.txt is a navigation file, not a blocking file. It points AI tools toward your best content. It does not stop any crawler from reading your site. Access control still belongs to robots.txt and your CDN.
Why is everyone suddenly talking about it?
Three reasons, and none of them are proof that it works.
First, the name echoes robots.txt and sitemap.xml, two files every marketer already knows. That makes llms.txt feel like the obvious next entry in a familiar set, so it spreads fast in SEO circles.
Second, the tools made it one click. Yoast now generates an llms.txt automatically for WordPress sites, and Wix rolled the file out globally for its users in 2026. When a plugin with millions of installs turns a feature on by default, the topic trends whether or not the feature does anything.
Third, everyone is anxious about AI search. Buyers are researching in ChatGPT and Perplexity, referral patterns are shifting, and marketers want a lever to pull. llms.txt is simple to publish, so it gets reached for first, ahead of harder work that actually moves the needle.
Does llms.txt actually work?
For AI search visibility, the current evidence is weak.
Start with adoption. A SE Ranking study of roughly 300,000 domains found about 10% carried an llms.txt file, and adoption was spread evenly across large and small sites rather than concentrated among leaders. Eighteen months after the idea appeared, it sits on about one site in ten.
Then look at whether the crawlers read it. OtterlyAI ran a controlled test and found that over 90 days and more than 60,000 AI bot visits, only about 0.1% touched the llms.txt file. Limy analyzed over 500 million AI bot events and reported the same pattern: the AI search crawlers overwhelmingly skip the file and crawl standard HTML instead.
Then look at the platforms. As of early 2026, no major AI company, including OpenAI, Google, Anthropic, Meta, and Mistral, has publicly committed to reading llms.txt in its production answer systems. Google has been the bluntest: its published guidance states that llms.txt has no effect on Search rankings or AI results, echoing an earlier comment from Google staff comparing it to the long-discredited keywords meta tag. Independent studies from SE Ranking and Trakkr found no link between having the file and being cited more often.
There is one fair counterpoint. Wix has argued that Google is in fact crawling and indexing llms.txt files at scale. That is probably true, and it corrects the flat claim that Google ignores the file. But crawling a file is not the same as using it to shape an answer, and Wix sells the feature it is defending. A crawler visiting a file tells you the file exists. It does not tell you the file changed a result.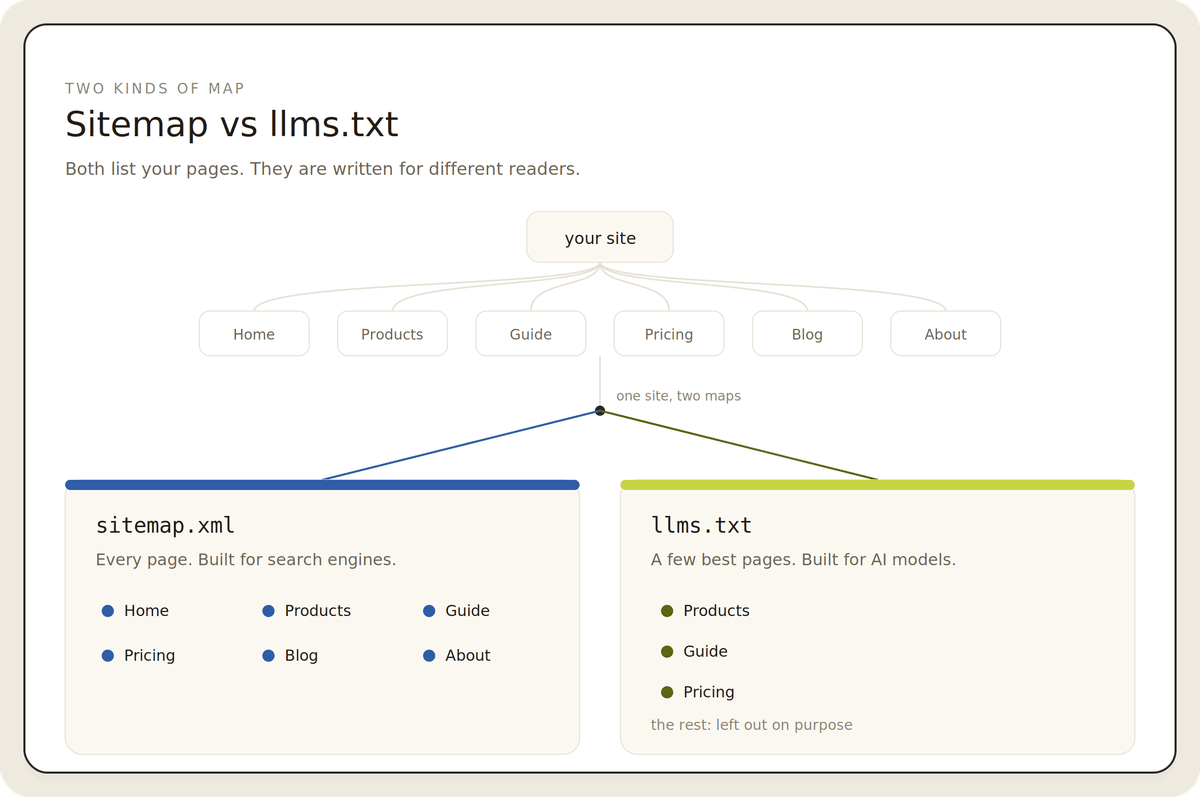
So why do companies still ship one?
Because the useful case for llms.txt is not AI search at all. It is developer tooling and agents, and there the value is real.
AI coding assistants read llms.txt routinely. Cursor, Windsurf, Claude Code, GitHub Copilot, and others look for it when pointed at a documentation site, then pull only the linked pages they need before writing code.
This is why Stripe, Vercel, Cloudflare, and Anthropic publish one. For a product whose users build integrations with AI assistants, a clean llms.txt is the difference between the assistant writing working code and inventing an endpoint that does not exist.
The second case is emerging fast. As buying agents start acting for people, they need a clean, machine-readable view of your catalog, pricing rules, availability, and policies. Publishing a file that routes an agent to canonical product pages, rather than making it parse a cluttered category page, is a plausible early advantage.
For anyone running commerce properties, this is the version of the story worth watching, because it is about being transactable by agents, rather than only visible in a chatbot. It is also where a read-only file meets its limit: to let agents act on a property rather than only read it, you need an authenticated layer like an MCP server, with permissions and approval built in.
Should you add llms.txt to your site?
Yes, with the right expectations.
Add it if it costs you an afternoon or a plugin toggle, especially if you have documentation, an API, or a product catalog that agents and coding tools might consume. Treat it as cheap insurance on a standard that may formalize the way robots.txt eventually did, since robots.txt was also a convention before any engine committed to it.
Do not add it expecting more AI citations next month. Do not build a separate markdown copy of every page, because indexable duplicates can dilute crawl budget and hurt the originals.
And do not let it climb your priority list above the work that has measurable impact. If you want to know whether anything reads yours, check your server logs for requests to /llms.txt from known AI user agents, or drop a honeypot link in the file and watch for hits.
Low cost, low risk, low current upside. Ship it, then move on to the work that actually moves visibility.
What actually moves AI visibility, no matter what
Every credible study points back to the same fundamentals. These are where your time earns a return, whether or not llms.txt ever matters.
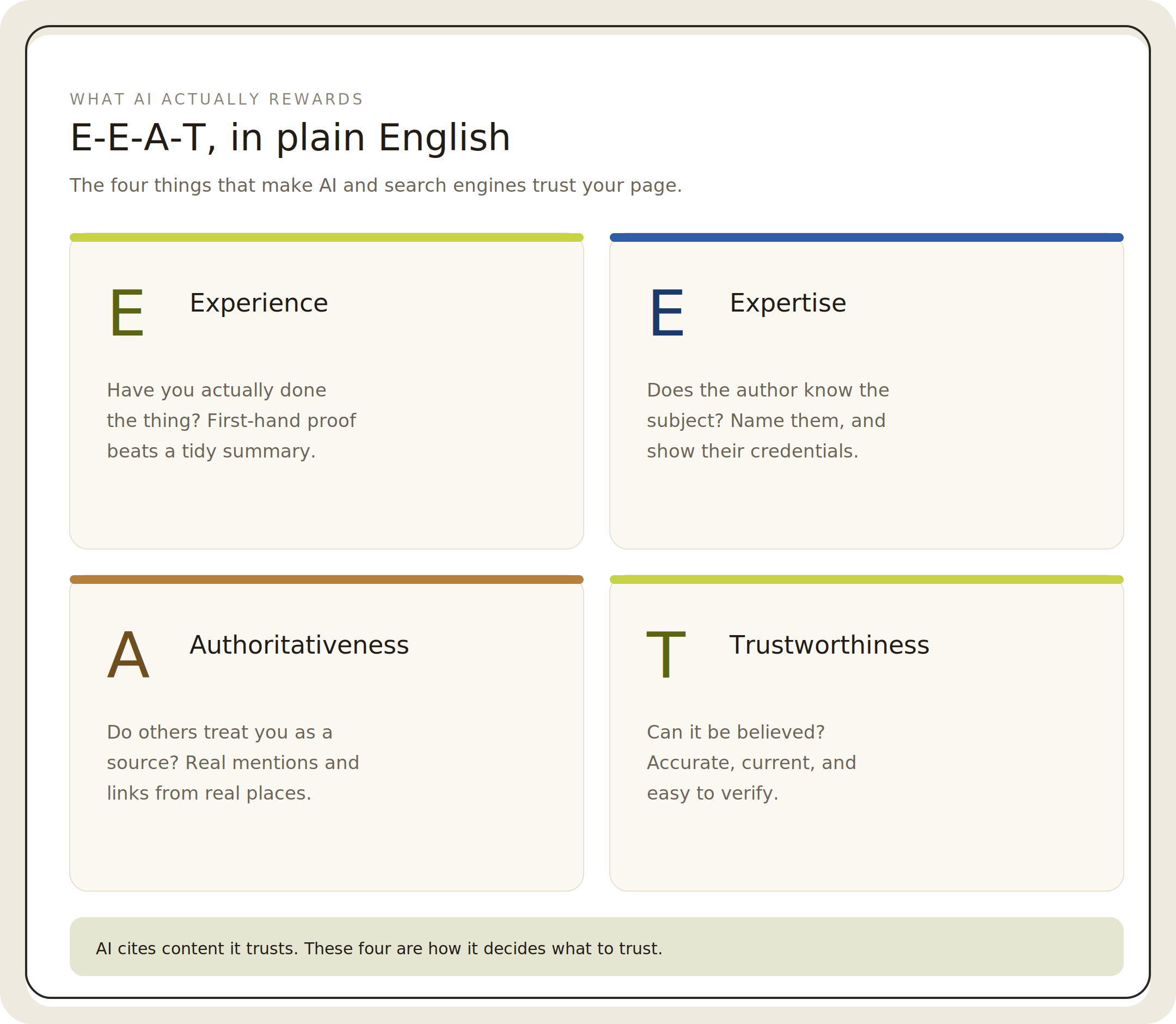
Publish original, expert-led content. AI systems and search engines both reward E-E-A-T: experience, expertise, authoritativeness, and trustworthiness. Show first-hand experience, name the author and their credentials, cite real sources, and add something a generic summary cannot.
 Answer questions directly and early. Answer engines extract clean, self-contained statements. Open sections with a direct answer, use question-form headings that match how people ask, and define terms plainly before you elaborate.
Answer questions directly and early. Answer engines extract clean, self-contained statements. Open sections with a direct answer, use question-form headings that match how people ask, and define terms plainly before you elaborate.
Keep your pages crawlable and technically sound. Fast loading, clean HTML, sensible internal links, and no accidental blocks in robots.txt. AI crawlers read your standard pages far more than any special file, so those pages have to be readable.
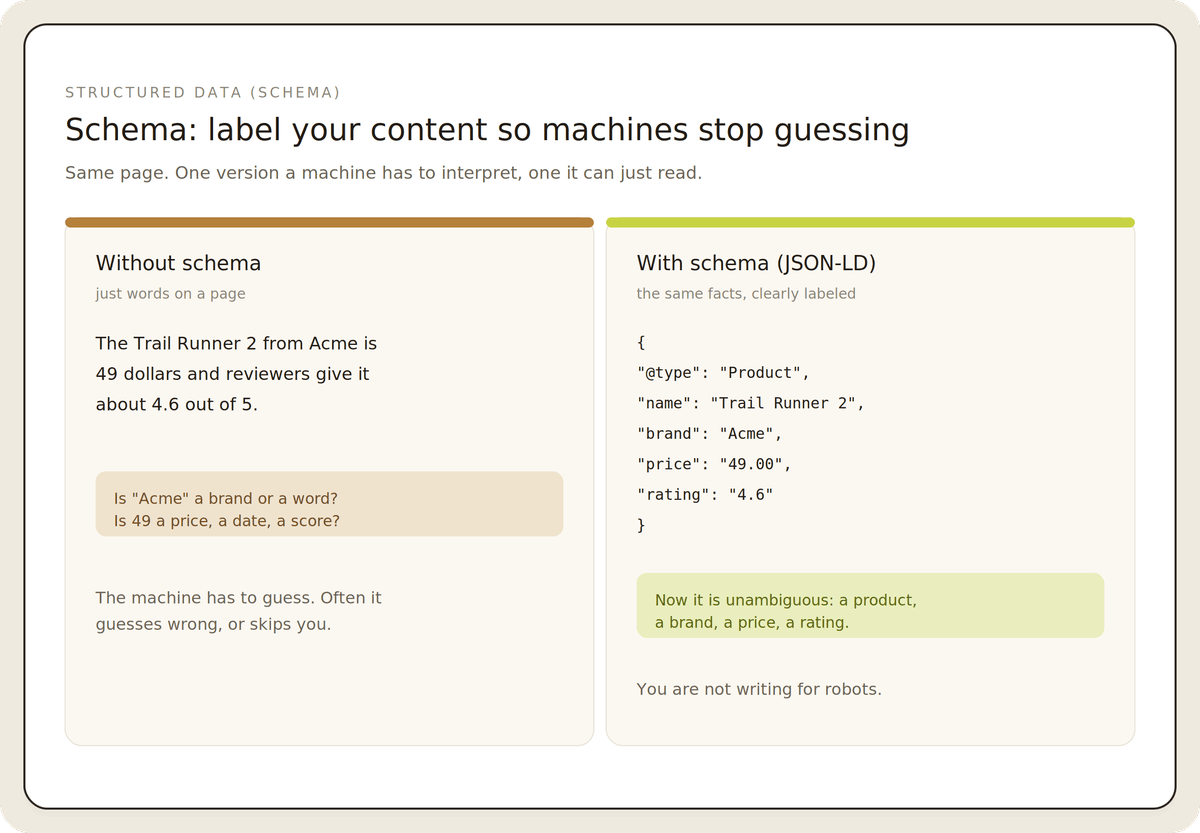
Use structured data. JSON-LD schema helps machines understand what your content is about and who wrote it, which supports more accurate citation. This has demonstrated impact where llms.txt does not.
Build real authority. Named entities, consistent facts across your site, genuine brand mentions, and credible external references do more for how AI systems trust and cite you than any file at your domain root.
Measure directionally. AI answers vary and attribution is patchy, so track citation frequency, inclusion in answers, and AI referral traffic over a long enough window to see a signal through the noise.
Frequently asked questions
Is llms.txt an official web standard?
No. It is a community convention proposed by Jeremy Howard in 2024, with no backing from the W3C, IETF, or any recognized standards body, and no enforcement mechanism. AI providers can read it or ignore it, and most currently ignore it.
Does llms.txt improve my Google rankings?
No. Google has stated it does not use llms.txt for search or its AI features. Ranking still depends on content quality, relevance, links, and technical health.
Will llms.txt get me cited more in ChatGPT or Perplexity?
There is no evidence it does today. Controlled studies found no link between having the file and being cited more often. Cited content tends to be authoritative, well structured, and directly answerable, with or without llms.txt.
Who actually reads llms.txt right now?
Mostly AI coding assistants such as Cursor, GitHub Copilot, and Claude Code, which use it to fetch documentation efficiently. This is the clearest real use case, which is why API-first companies ship it.
Is there any downside to adding it?
Very little, if you do it correctly. The main risk is wasting time over-engineering it or creating duplicate indexable copies of every page. Publish a simple file, keep it accurate, and spend the saved effort on content and structured data.
What is the difference between llms.txt and robots.txt?
robots.txt controls access: it tells crawlers which paths they may fetch. llms.txt is about navigation: it points AI systems toward your best content. One is a gate, the other is a map. Neither blocks a crawler that chooses not to comply.
See how multi-property operators run every site from one platform. Book a demo with a Core dna specialist.
Summarize with

